
Các nhà nghiên cứu tại Google Research vừa công bố thuật toán TurboQuant vào cuối tháng 3 năm 2026 nhằm giải quyết triệt để cuộc khủng hoảng thiếu hụt RAM trên toàn cầu. Công nghệ này có khả năng nén bộ nhớ làm việc của các mô hình trí tuệ nhân tạo xuống ít nhất 6 lần mà không làm suy giảm độ chính xác hay hiệu năng xử lý. Bằng cách kết hợp các phép toán học phức tạp để tối ưu hóa bộ nhớ đệm dữ liệu, Google đang tạo ra một bước ngoặt giúp việc vận hành AI trở nên rẻ hơn và nhanh hơn đáng kể so với các phương thức truyền thống.
Nỗ lực giải cứu ngành phần cứng khỏi cơn khát bộ nhớ
Trong bối cảnh nhu cầu sử dụng trí tuệ nhân tạo tăng vọt, các trung tâm dữ liệu đang đối mặt với tình trạng thiếu hụt linh kiện bộ nhớ nghiêm trọng. Việc các mô hình ngôn ngữ lớn đòi hỏi lượng RAM khổng lồ để lưu trữ dữ liệu tạm thời trong quá trình xử lý đã đẩy giá phần cứng lên mức cao kỷ lục. TurboQuant xuất hiện như một giải pháp cứu cánh cho ngành công nghiệp khi cho phép các máy tính cũ hoặc cấu hình thấp vẫn có thể chạy được những ứng dụng AI phức tạp.
Dù hiện tại thuật toán này vẫn đang trong giai đoạn thử nghiệm tại phòng thí nghiệm, những kết quả ban đầu cho thấy triển vọng thay đổi hoàn toàn cục diện thị trường. Thay vì phải đầu tư hàng tỷ USD vào việc mở rộng cơ sở hạ tầng vật lý, các doanh nghiệp giờ đây có thể tận dụng sức mạnh của phần mềm để tối ưu hóa nguồn lực sẵn có. Google dự kiến sẽ công bố chi tiết kỹ thuật của TurboQuant tại hội nghị ICLR 2026 diễn ra vào tháng tới để cộng đồng công nghệ cùng kiểm chứng.
Đột phá từ tư duy toán học thay vì nâng cấp chip
Cốt lõi của sự thay đổi này nằm ở cách Google xử lý các vector dữ liệu vốn là nền tảng để AI hiểu và phản hồi thông tin. Thông thường, các vector này chiếm dụng rất nhiều không gian lưu trữ và làm chậm tốc độ truy xuất. Thuật toán mới đã thay đổi hoàn toàn cách tiếp cận bằng việc sử dụng tọa độ cực thay cho hệ tọa độ vuông góc quen thuộc.
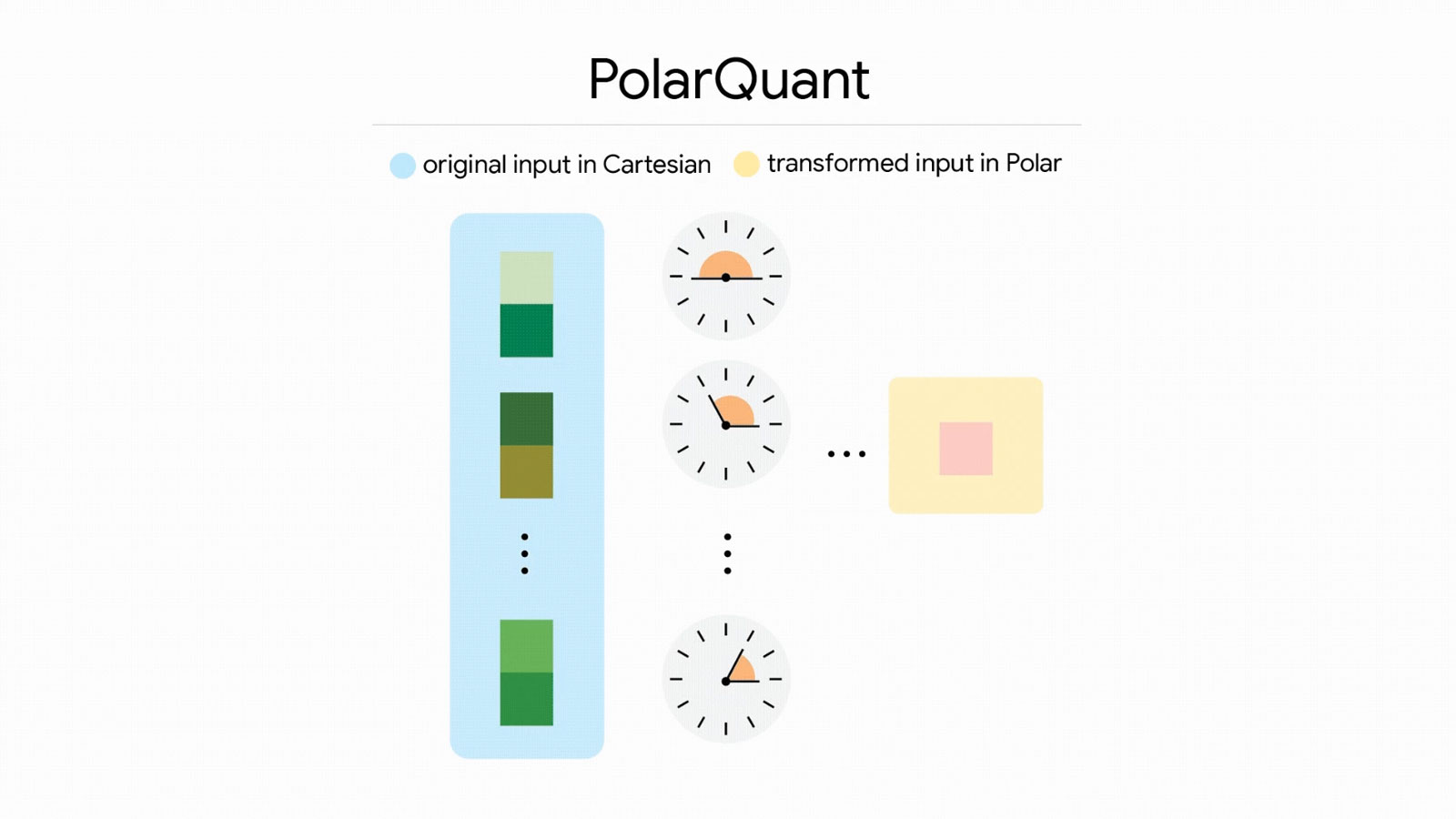
Phương pháp mang tên PolarQuant này cho phép máy tính biểu diễn dữ liệu dưới dạng các góc và bán kính thay vì các điểm tọa độ phức tạp. Việc này giúp loại bỏ những bước tính toán trung gian không cần thiết và giảm bớt gánh nặng cho bộ vi xử lý. Đi kèm với đó là kỹ thuật QJL giúp xử lý những sai số nhỏ phát sinh trong quá trình nén bằng một mẹo toán học chỉ tiêu tốn đúng 1 bit bộ nhớ. Sự kết hợp này tạo ra một hệ thống nén dữ liệu gần như hoàn hảo, giúp AI ghi nhớ được nhiều thông tin hơn trong một không gian lưu trữ nhỏ hẹp hơn rất nhiều.
Hiệu năng thực tế và những con số ấn tượng của TurboQuant
Các thử nghiệm thực tế trên những dòng chip xử lý đồ họa mạnh mẽ nhất hiện nay như H100 cho thấy kết quả vô cùng khả quan. TurboQuant giúp tăng tốc độ phản hồi của AI lên gấp 8 lần so với việc không nén dữ liệu. Đáng chú ý là thuật toán này có thể hoạt động tốt trên cả những mô hình mã nguồn mở như Gemma hay Mistral mà không cần phải thực hiện lại quá trình đào tạo tốn kém.
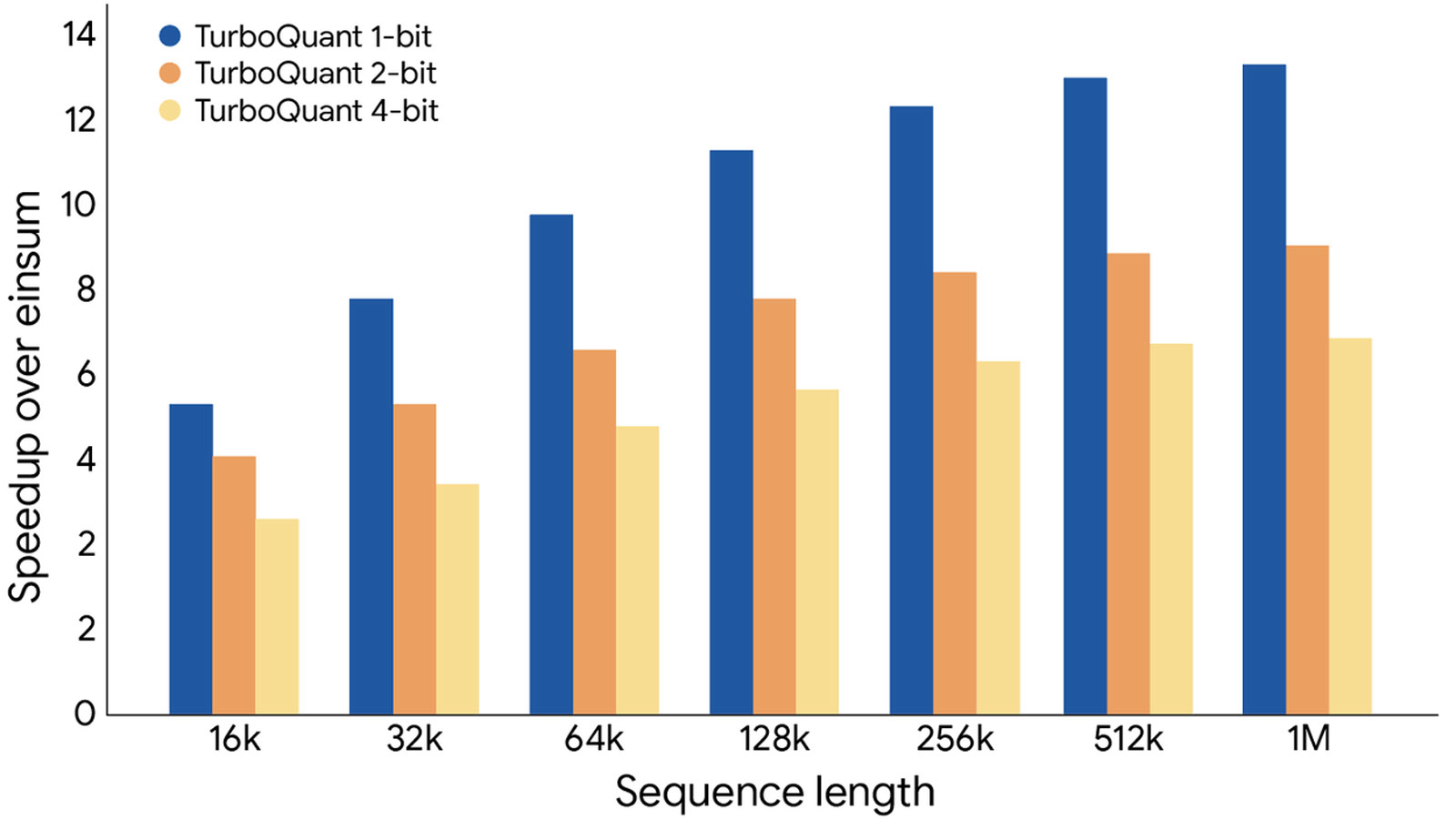
Việc giảm mức độ sử dụng bộ nhớ xuống chỉ còn 3 bit mỗi đơn vị dữ liệu mà vẫn duy trì được trí thông minh của mô hình là một thành tựu chưa từng có. Điều này giúp các hệ thống tìm kiếm vector của Google hoạt động mượt mà hơn, cho phép người dùng nhận được câu trả lời chính xác trong thời gian thực. Giới chuyên gia nhận định đây chính là thời khắc chuyển mình của Google, tương tự như cách các đối thủ cạnh tranh đã từng tối ưu hóa chi phí vận hành để gây áp lực lên thị trường.
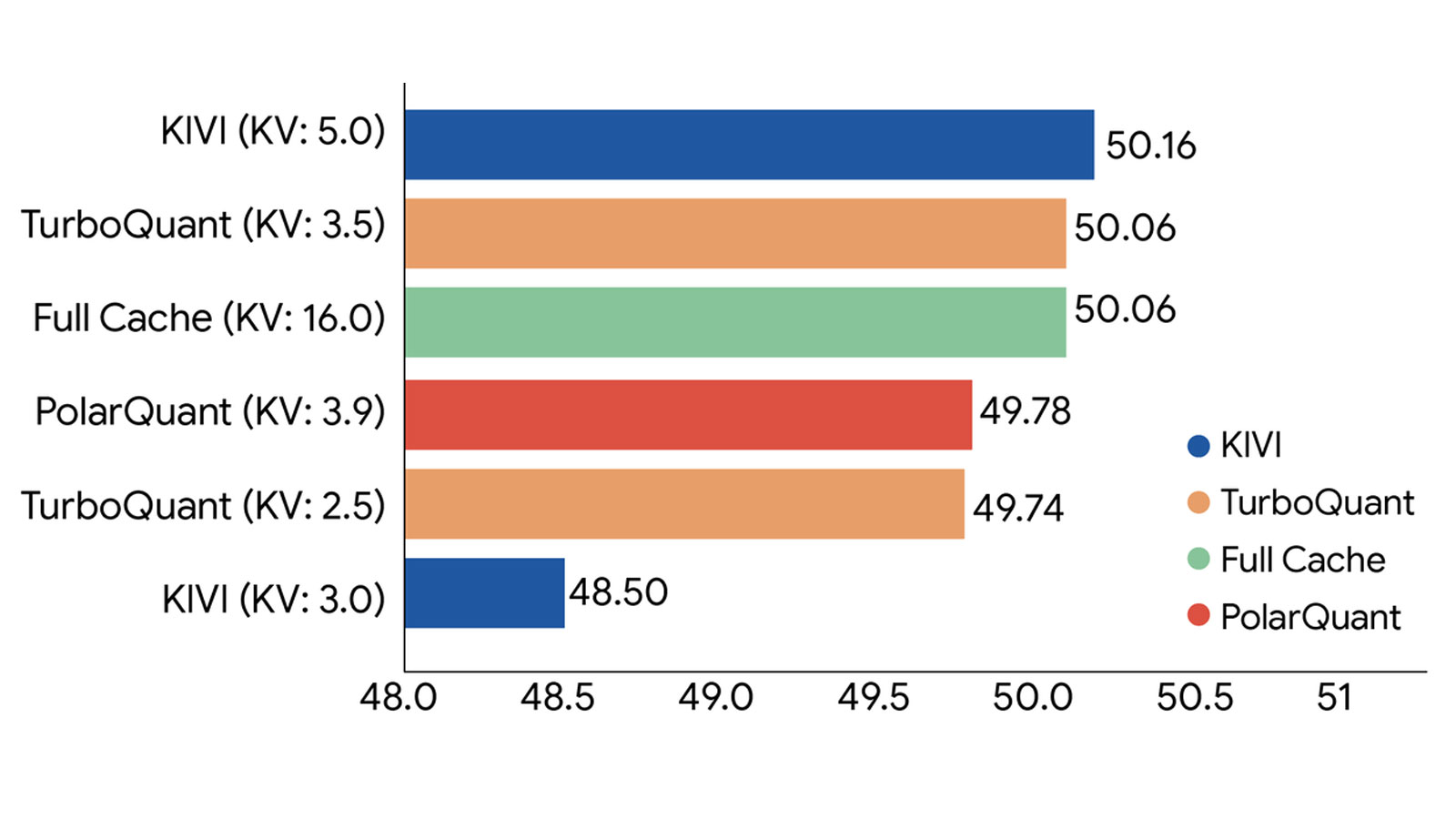
Tầm ảnh hưởng đến tương lai ngành tìm kiếm và AI
Sự ra đời của TurboQuant không chỉ đơn thuần là một cải tiến về mặt kỹ thuật mà còn mở ra hướng đi mới cho công nghệ tìm kiếm ngữ nghĩa. Khi dữ liệu được nén gọn và truy xuất nhanh, việc tìm kiếm dựa trên ý định và ngữ cảnh sẽ trở nên phổ biến hơn thay vì chỉ dựa vào từ khóa như trước đây. Điều này có ý nghĩa quan trọng trong việc cá nhân hóa trải nghiệm người dùng và nâng cao chất lượng thông tin trên môi trường internet.
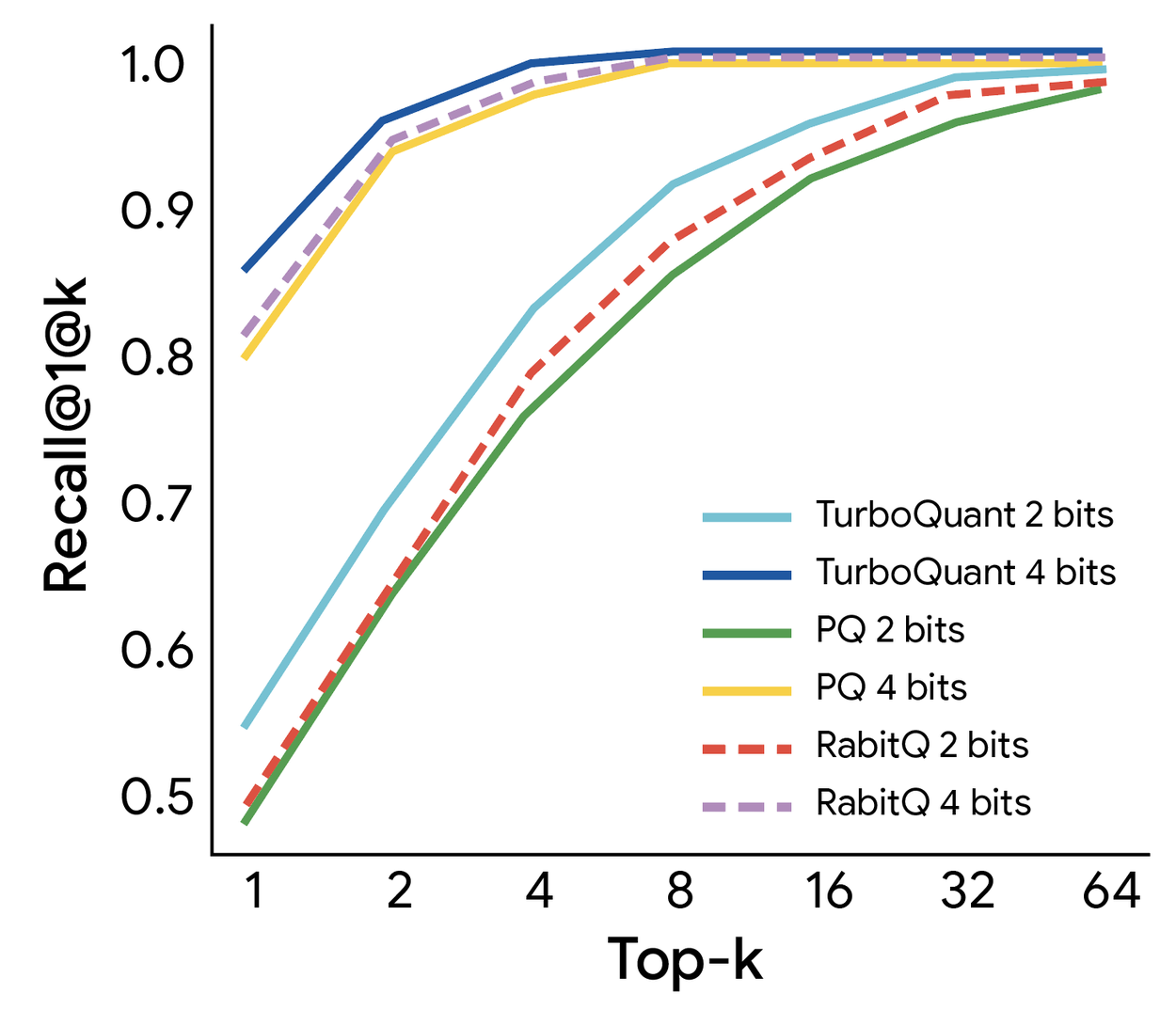
Trong tương lai gần, khi thuật toán này được triển khai rộng rãi, chi phí vận hành các dịch vụ AI sẽ giảm xuống mức thấp nhất từ trước đến nay. Người dùng phổ thông sẽ là những đối tượng được hưởng lợi trực tiếp khi các ứng dụng trí tuệ nhân tạo trở nên thông minh hơn, phản hồi nhanh hơn và có thể hoạt động ngay trên các thiết bị cá nhân mà không cần phụ thuộc quá nhiều vào điện toán đám mây. Đây là nền tảng vững chắc để Google tiếp tục duy trì vị thế dẫn đầu trong kỷ nguyên công nghệ mới.







Comments