
Các công cụ AI đã có những bước tiến dài khi có thể giải các bài toán phức tạp hay hỗ trợ lập trình phần mềm chỉ trong tích tắc. Tuy nhiên, có một thực tế là định dạng tệp PDF quen thuộc lại đang trở thành một bài toán khó đối với cả những mô hình AI tiên tiến nhất hiện nay. Dù rất phổ biến trong công việc hàng ngày, cấu trúc đặc thù của PDF vẫn khiến các hệ thống AI dễ gặp lỗi hoặc đưa ra thông tin thiếu chính xác khi xử lý các tài liệu dài và phức tạp.
Những thách thức thực tế khi xử lý tệp PDF
Vấn đề này trở nên rõ ràng hơn khi các cơ quan chức năng tại Mỹ công bố hàng triệu trang tài liệu dưới dạng PDF trong các vụ việc pháp lý gần đây. Luke Igel, người đồng sáng lập startup AI Kino, chia sẻ rằng việc tìm kiếm thông tin trong mớ hỗn độn này là một thử thách rất lớn. Dù các tài liệu đã được xử lý qua công nghệ nhận dạng chữ viết (OCR), nhưng kết quả thu được thường bị lỗi định dạng, khiến các luồng hội thoại hoặc lịch trình sự kiện bị xáo trộn. Người dùng gần như không có một công cụ tìm kiếm hiệu quả mà phải dựa vào sự may mắn để tìm đúng nội dung mình cần trong hàng triệu trang tệp tin.
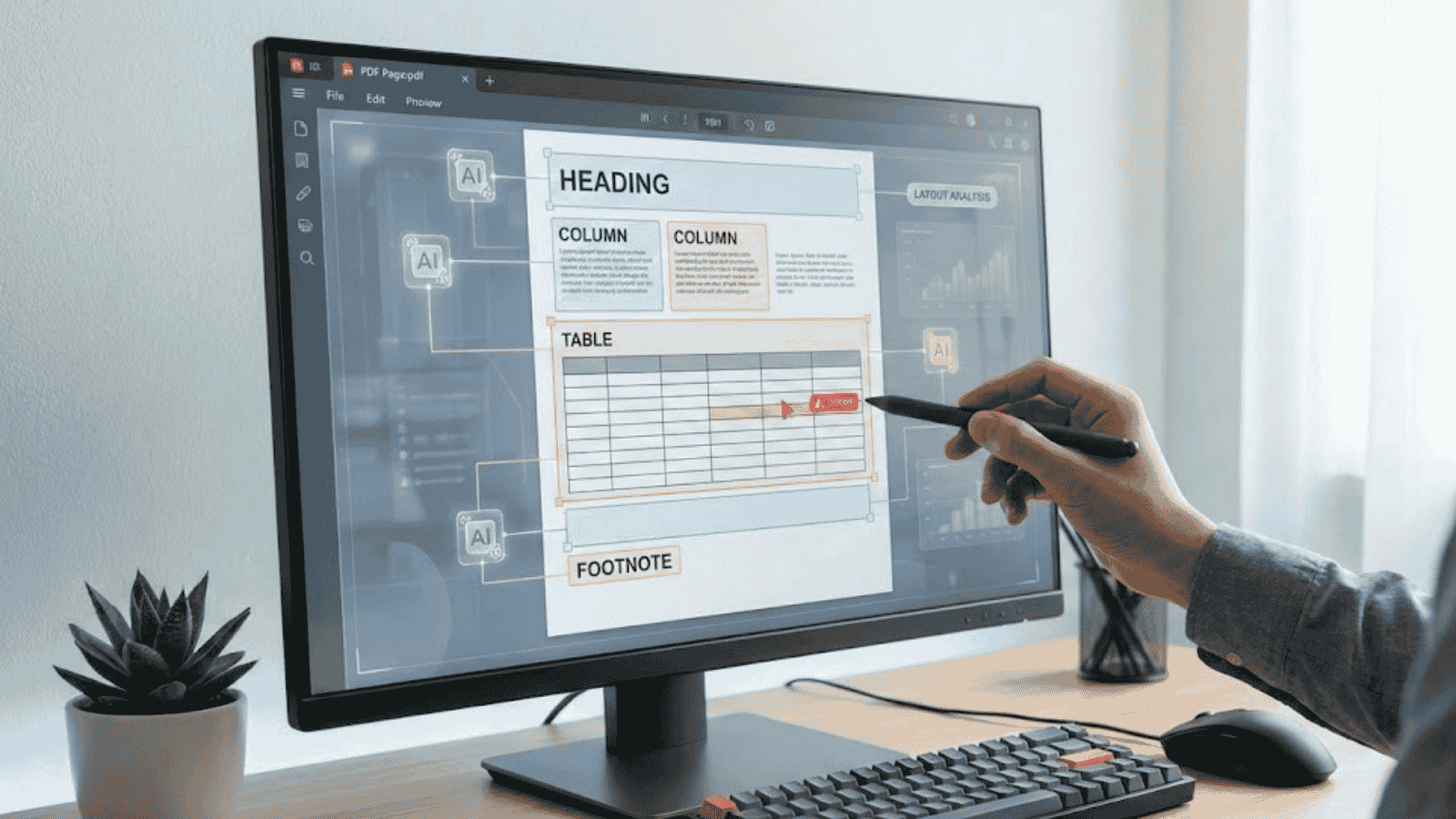
Lý do AI khó “hiểu” được cấu trúc của PDF
Edwin Chen, CEO của công ty dữ liệu Surge, nhận định rằng việc đọc hiểu PDF là một trong những hạn chế thực tế làm giảm đi sự hữu ích của AI trong đời sống. Nguyên nhân cốt lõi nằm ở chỗ PDF được thiết kế để giữ nguyên cách hiển thị hình ảnh và bố cục trên mọi thiết bị, chứ không phải để máy tính dễ dàng đọc dữ liệu. Khi AI quét một tệp PDF, nó phải tự mình phân tích đâu là tiêu đề, đâu là bảng biểu và thứ tự đọc các cột văn bản như thế nào cho đúng. Chỉ cần một bảng số liệu bị lệch dòng hoặc văn bản chia cột không rõ ràng, AI sẽ dễ dàng hiểu sai hoàn toàn nội dung gốc.
Hiện nay, các nhà phát triển đang nỗ lực cải thiện khả năng này bằng cách huấn luyện AI nhìn nhận tài liệu như một bức ảnh để hiểu bố cục trước khi đọc nội dung chữ. Tuy nhiên, trong thời gian chờ đợi công nghệ hoàn thiện, người dùng cần thận trọng khi yêu cầu AI tóm tắt các văn bản quan trọng như hợp đồng pháp lý hay báo cáo tài chính có nhiều bảng biểu. Để có kết quả tốt hơn, thay vì đưa cả một tệp dài, bạn có thể yêu cầu AI xử lý từng trang cụ thể để giảm thiểu sai sót.
Việc AI xử lý tốt tệp PDF không chỉ là một vấn đề kỹ thuật mà còn là chìa khóa để khai thác kho dữ liệu khổng lồ mà con người đã lưu trữ bấy lâu nay. Mặc dù vẫn còn những hạn chế nhất định, nhưng những nỗ lực cải thiện công nghệ hiện tại hứa hẹn sẽ giúp việc quản lý và tìm kiếm tài liệu trở nên đơn giản và chính xác hơn trong tương lai gần.
Theo: The Verge





Comments